
The Problem: Filling in the Blank
Imagine you’re writing a Python function and you get stuck halfway through. You know what the function is supposed to do (the beginning), and you can see the end of the file (the continuation), but the middle is missing. You ask an AI coding assistant to fill in that gap.
Here’s the interesting question: should you show the AI only the beginning, or should you show it both the beginning and the end?
That’s exactly what this paper investigates.
Two Strategies, One Model
I tested two ways of prompting the same AI model, DeepSeekCoder 1.3B (a small but capable open-source code model):
Left-to-Right (LTR): the classic approach. Give the model only what comes before the missing piece, and let it generate forward. It’s like asking someone to finish a sentence without telling them how the paragraph ends.
Fill-in-the-Middle (FIM): a smarter framing. Give the model the code before the gap and the code after the gap, then ask it to fill only what’s missing in the middle. The model was specifically trained to handle this format using special tokens that mark “here is the beginning”, “here is the end”, “now fill the hole.”
The diagram below shows both strategies side by side on a real example from the evaluation:

On the left, LTR only sees the prefix and blindly outputs return False, technically valid Python but logically wrong. On the right, FIM sees both the prefix and the suffix (the code that must follow), so it correctly generates the missing loop that bridges the two.
The Benchmark: HumanEval Infilling
To measure which approach works better, I used HumanEval Infilling, a standard benchmark where Python functions have been deliberately split at different points, creating gaps of varying difficulty.
For each of the 500 test cases, I ran the model with both strategies and checked four things:
- Syntax: does the generated code parse without errors?
- Unit tests: does the completed function actually produce the right answers?
- No duplicate returns / variable declarations: did the model accidentally repeat something already in the code?
- Boundary coherence: does the generated piece connect cleanly to the code around it, without weird overlaps?
Results: FIM Wins, and It’s Not Close
The numbers tell a clear story.
| Metric | LTR | FIM |
|---|---|---|
| Syntax valid | 62.8% | 89.0% |
| Unit tests passing | 21.2% | 64.4% |
| No duplicate return | 62.8% | 88.8% |
| No duplicate variable | 62.8% | 89.0% |
| Boundary coherent | 100.0% | 99.6% |
| Overall score | 61.9% | 86.2% |
FIM passed unit tests more than three times as often as LTR (64.4% vs 21.2%). Out of 500 tasks, FIM produced 322 correct solutions while LTR only managed 106.
Chart 1: Pass rate for each quality metric
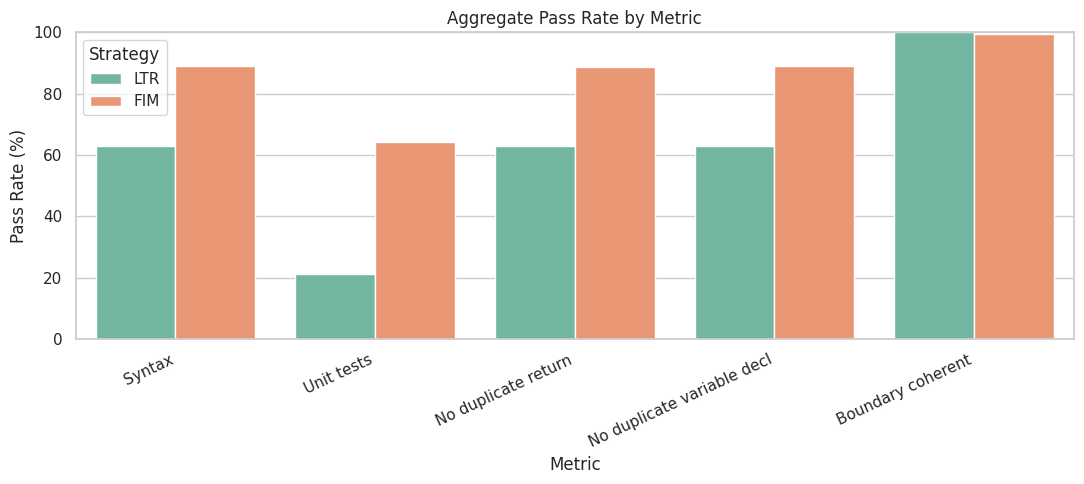
The bar chart above shows how FIM (orange) consistently outperforms LTR (green) across every metric except boundary coherence, where both are essentially tied. The biggest gap is on unit tests, the hardest measure because it requires the code to actually run correctly, not just look right.
Chart 2: Quality score across individual tasks
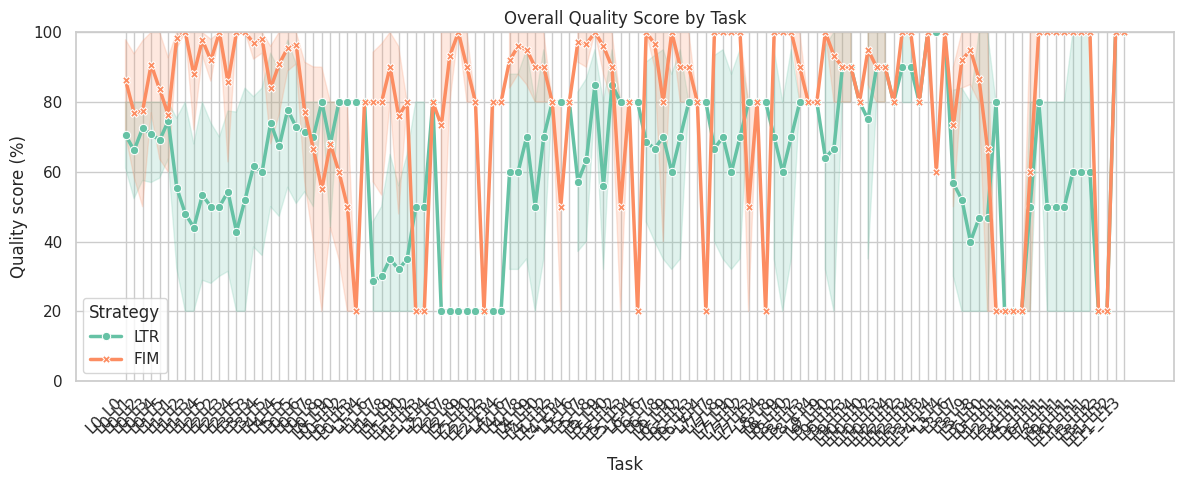
This line chart plots the quality score for each of the 500 test tasks. LTR (green) is much more volatile, with lots of tasks scoring near zero. FIM (orange) stays higher and more consistent throughout.
Why Does FIM Do Better?
The intuition is straightforward: when you know where you need to end up, you make better choices along the way.
The LTR model sees only the function signature and docstring. Without context about what comes next, it often generates plausible-looking code that doesn’t connect properly to the rest of the function, or it gives up and writes something trivially wrong (like just return False).
The FIM model can read the suffix and work backwards from the ending. It knows, for example, that a loop variable idx2 will be needed shortly, so it sets that up correctly. It’s a fundamentally more constrained (and therefore more solvable) problem.
A concrete example from the results: for a task asking the model to complete the missing lines in a function that checks whether any two numbers in a list are close together, the LTR model just output return False (wrong). The FIM model correctly generated for idx, elem in enumerate(numbers): which was exactly the line needed to bridge the gap (PASS).
What This Means in Practice
Modern AI coding tools like GitHub Copilot or Cursor already use FIM-style prompting under the hood when you’re editing in the middle of a file. This experiment confirms, on a small open-source model, that this design choice matters enormously. It’s the difference between a 21% and a 64% success rate on real code.
For anyone building or fine-tuning code generation models: make sure your model supports FIM, and make sure your prompts use it when you have context on both sides of the gap.
Full paper: term_paper.pdf · Evaluation notebook: deepseek_ltr_vs_fim_eval.ipynb